ini (Anil et al., 2023), and LLaMA (Touvron et al., 2023) have
analysis (Wang et al., 2018), question answering (Peng et al., 2023), and autonomous agents (Chen et al., 2024).
![]()
mimicry (Lonergan, 1957; Sternberg, 1983). Given LLMs’
ings (Miller, 1967; De Deyne et al., 2023), a fine-grained lan-

Figure 1: An example from LeSC dataset. Within the gray box are the inputs, comprising a prompt, a question, and provided options, and ’A’, ’B’, ’C’ refer to ’low in price’, ’unwilling to spend money’, ’of poor quality; inferior’, respectively. Within the green box, the answer of ChatGPT is ’A’, inconsistent with the correct answer ’C’.
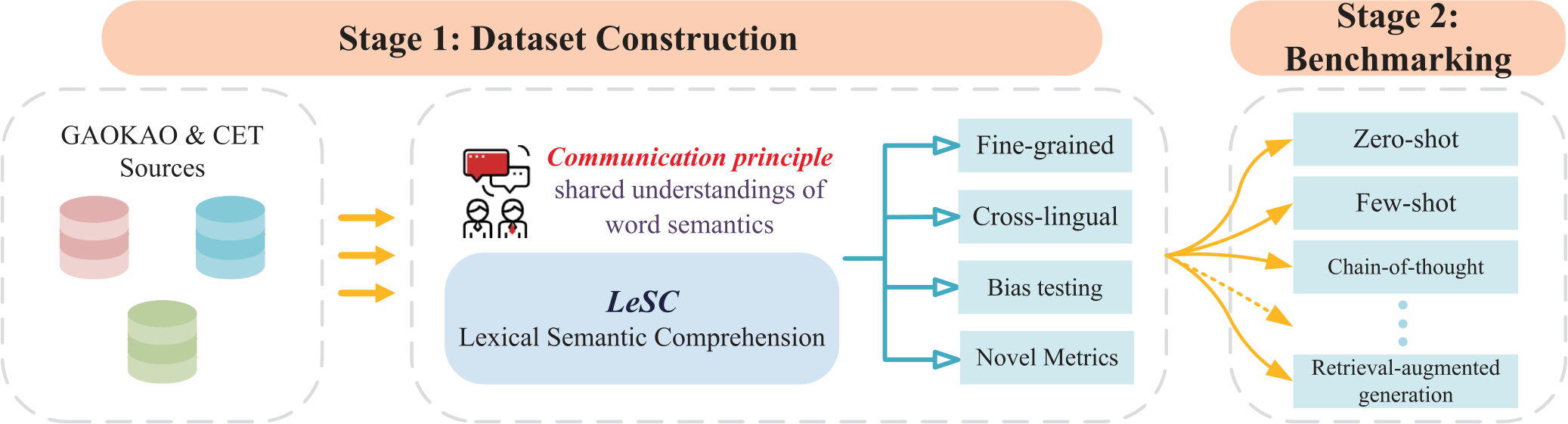
Figure 2: The workflow of LeSC. In stage 1, we first construct the LeSC dataset using GAOKAO and CET sources. After that, in stage 2, we employ advanced strategies to obtain benchmarking results for LLMs.
![]()
lier explorations (Brown et al., 2020; Bubeck et al., 2023) have
ing (Wei et al., 2022; Kojima et al., 2022), a type of few-shot
ChatGPT (OpenAI, 2023). Furthermore, (Kojima et al., 2022),
dated knowledge (Huang et al., 2023; Kandpal et al., 2023).
solution these years (Gao et al., 2023; Zhao et al., 2024). By
inal input (Chen et al., 2017; Qu et al., 2021). Recent ex-
express it as x = [t11, t21, ..., tnk], where t ji denotes the i-th word
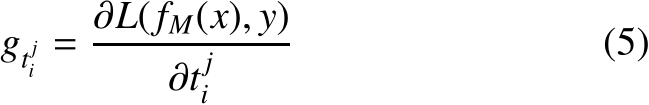
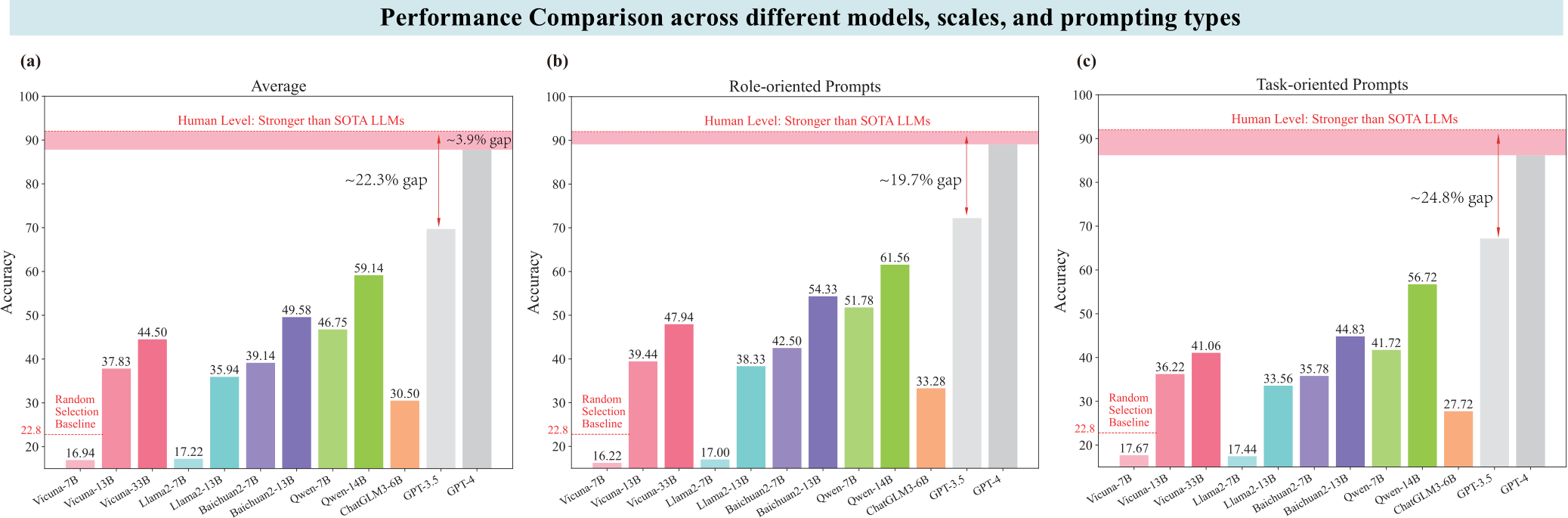
Figure 3: Results for the overall performance on LeSC dataset under different settings. Tile ’Average’, ’Role-oriented Prompts’, and ’Task-oriented Prompts’ refer to the accuracy (![]() 100) of LLMs on all, role-oriented, task-oriented prompts, respectively. We also plot the performance levels of humans (92%) and random selection (23%) as a reference.
100) of LLMs on all, role-oriented, task-oriented prompts, respectively. We also plot the performance levels of humans (92%) and random selection (23%) as a reference.
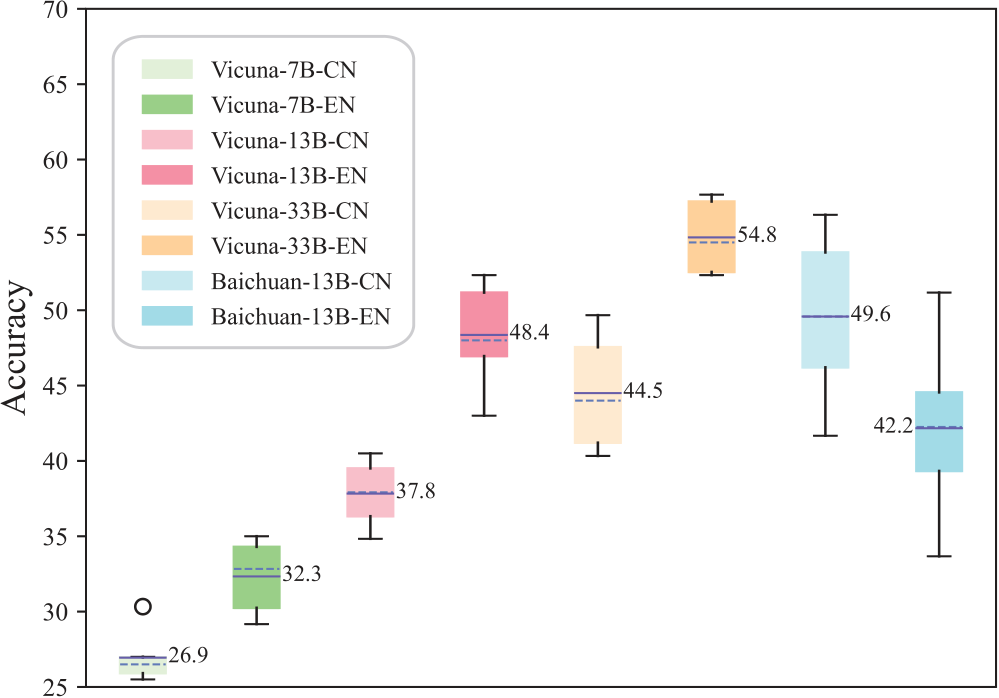
Figure 4: Accuracy (![]() 100) for different model scales and architectures, and pretraining corpora concerning languages (CN, EN) of options.
100) for different model scales and architectures, and pretraining corpora concerning languages (CN, EN) of options.
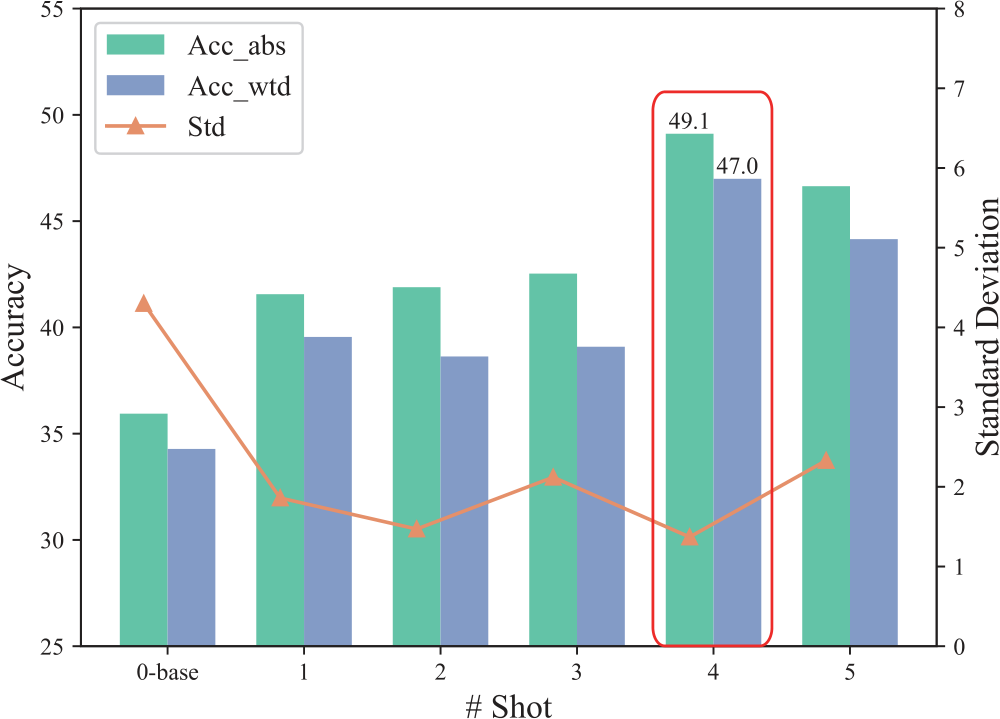
Figure 5: Results on LeSC corresponding to k (shot) in few-shot prompting. ’Acca ’, ’Accwtd’, ’Std’ refer to absolute and weighted accuracy, and standard deviation, respectively.
Table 1: Absolute and weighted accuracies (![]() 100) with prompting techniques on the LeSC dataset. ‘Modified’, ‘Ins-hint’, ‘Ins-false’, and ‘Ins-false-hint’ are all instructed prompting, which denotes more easy problems after modification, instruction with correct understanding hints, false information, false information plus correct hints like ‘Feel free to ignore false information in the inputs’, respectively. Results with bold and underlining labels are better than others. Here we consider the vicuna-family models with three sizes, 7B, 13B, 33B.
100) with prompting techniques on the LeSC dataset. ‘Modified’, ‘Ins-hint’, ‘Ins-false’, and ‘Ins-false-hint’ are all instructed prompting, which denotes more easy problems after modification, instruction with correct understanding hints, false information, false information plus correct hints like ‘Feel free to ignore false information in the inputs’, respectively. Results with bold and underlining labels are better than others. Here we consider the vicuna-family models with three sizes, 7B, 13B, 33B.
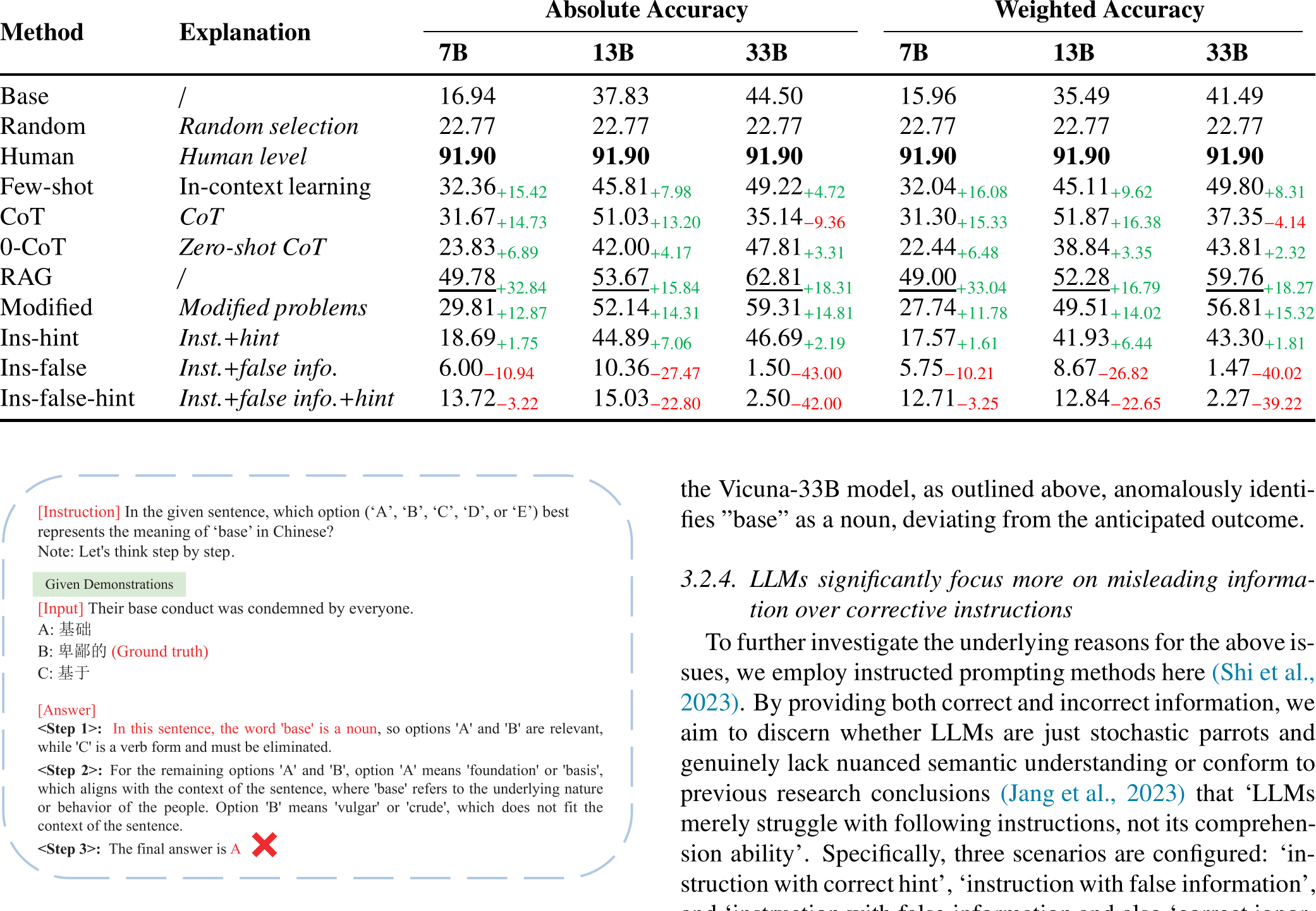
Figure 6: An example from LeSC dataset that showcases the CoT result of Vicuna-33B. Option ’A’, ’B’, ’C’ refer to ’the part on which it rests or is sup- ported’, ’contemptibly low in position’, ’to use as a foundation’, respectively.
in POS tagging tasks (Chang et al., 2023; Bubeck et al., 2023),
Table 2: Response analysis based on attention visualization. The green and red colors in ’pred’ denote right and wrong answers, respectively. Color intensity denotes attention weights (heavier color means larger weights). False information (’Ins-false’) results in incorrect responses. Even with correct ignoring hints (’Ins-false-hint’), LLMs directly disregard them, remaining influenced by misleading information.”
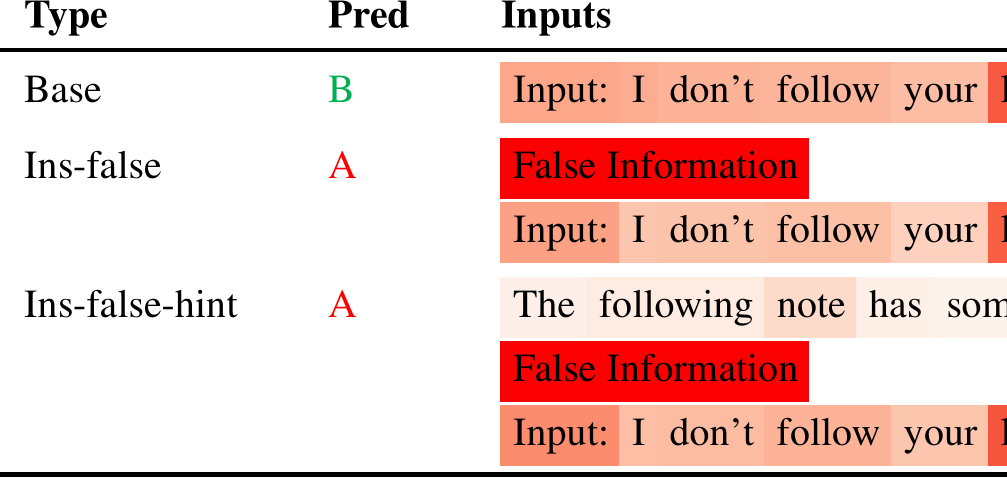
Table 3: Comparison between zero-shot performance and translation process, involving initial translation acquisition for a candidate problem, followed by GPT-4 evaluation for translation accuracy.
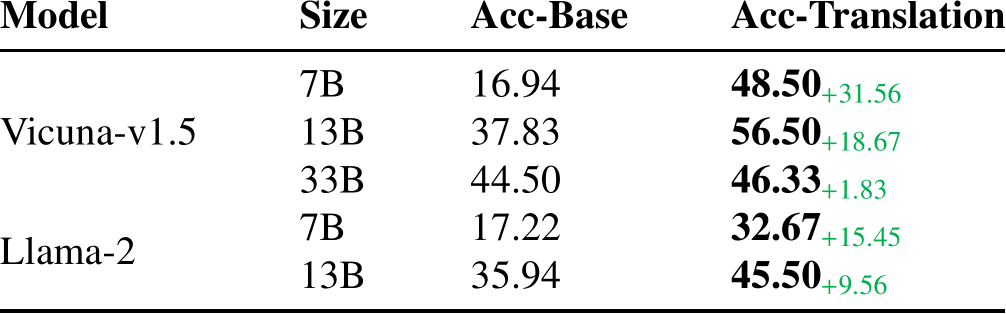
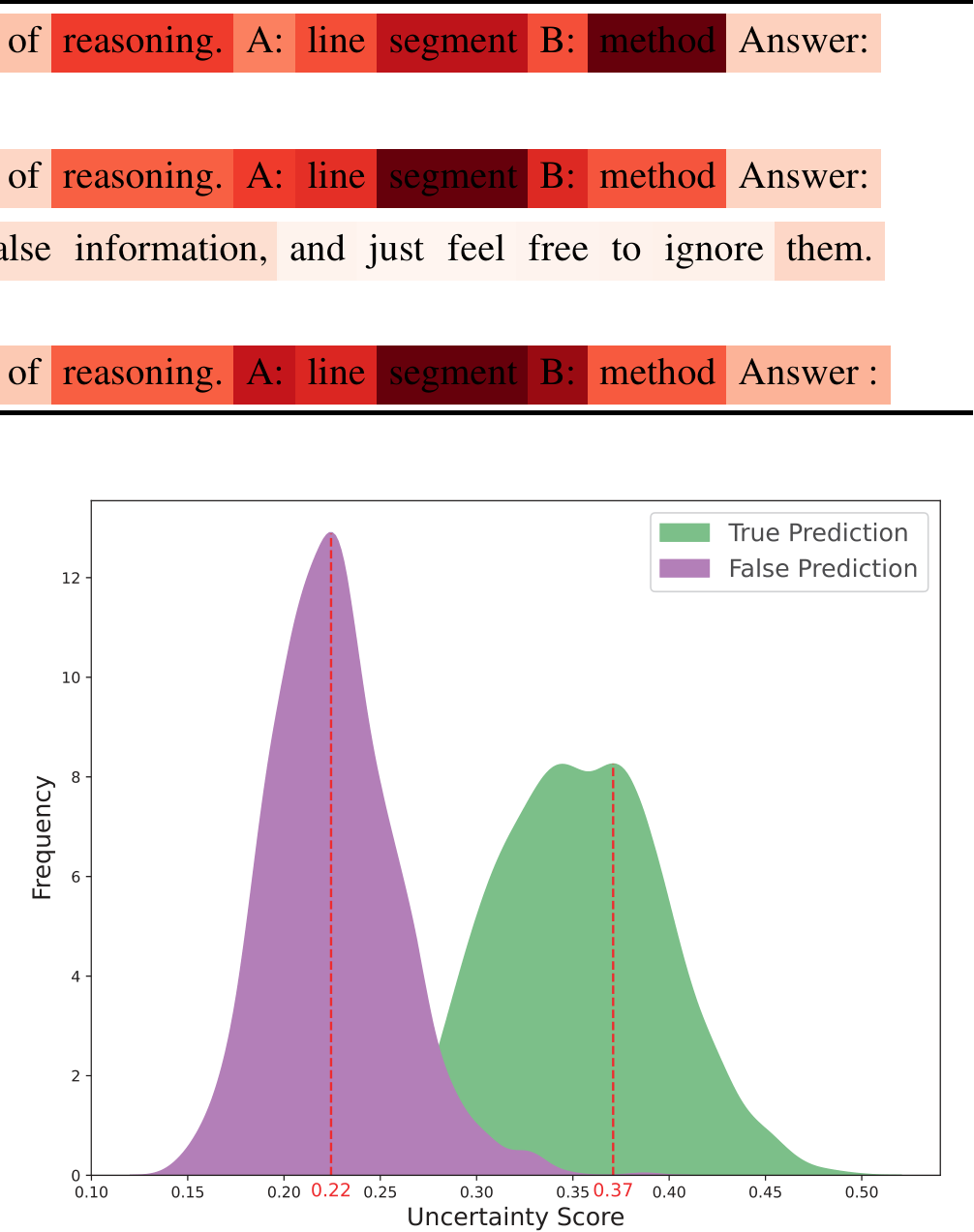
Figure 7: Comparison between correctly answered and incorrectly answered questions on uncertainty. The results show that LLMs tend to give false re- sponses while exhibiting low uncertainty and heightened confidence.
![]()
Table 4: Output example for different models on a LeSC problem and corresponding zero-shot and CoT solutions, which may potentially contain false or hallucination contents. The left answers correspond to zero-shot, while the solutions and answers on the right correspond to CoT. And the black (e.g. C ![]() colors (e.g. A
colors (e.g. A ![]() ) denote right and wrong answers, respectively. Note that options ’A:
) denote right and wrong answers, respectively. Note that options ’A: ![]() ’ refer to ’A: the invisible gaseous substance surrounding the earth, a mixture mainly of oxygen and nitrogen’, ’B: the appearance or impression given by a person or thing’, ’C: to make (a grievance or problem) public’, ’D: to dry (something) by exposing it to air’.
’ refer to ’A: the invisible gaseous substance surrounding the earth, a mixture mainly of oxygen and nitrogen’, ’B: the appearance or impression given by a person or thing’, ’C: to make (a grievance or problem) public’, ’D: to dry (something) by exposing it to air’.

![]()
![]()
![]()
it is used in this sentence. <Step 3>: Since none of the options are suitable, the answer is ’None of the above’ ![]()
curately. <Step 3>: Finally, considered above factors, I believe that the correct response should include ”air” ![]()
Anil, G.T.G.R., Borgeaud, S., Wu, Y., et al., 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 .
Asai, A., Wu, Z., Wang, Y., Sil, A., Hajishirzi, H., 2024. Self-RAG: Learn- ing to retrieve, generate, and critique through self-reflection, in: The Twelfth International Conference on Learning Representations. URL: https://openreview.net/forum?id=hSyW5go0v8.
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., Hui, B., Ji, L., Li, M., Lin, J., Lin, R., Liu, D., Liu, G., Lu, C., Lu, K., Ma, J., Men, R., Ren, X., Ren, X., Tan, C., Wang, S., Wang, W., Wu, S., Xu, B., Xu, J., Yang, A., Yang, H., Yu, B., Yuan, H., Yuan, Z., Zhang, J., Zhang, X., Zhang, Y., Zhang, Z., Zhou, C., Zhou, J., Zhou, X., Zhu, T., 2023. Qwen technical report. arXiv preprint arXiv:2309.16609 .
Baichuan, 2023. Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305 URL: https://arxiv.org/abs/2309.10305.
Bender, E.M., Gebru, T., McMillan-Major, A., Shmitchell, S., 2021. On the dangers of stochastic parrots: Can language models be too big?, in: Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, pp. 610–623.
Borji, A., 2023. Stochastic parrots or intelligent systems? a perspective on true depth of understanding in llms. A Perspective on True Depth of Understanding in LLMs (July 11, 2023) .
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al., 2020. Language models are few-shot learners. Advances in neural information processing systems 33, 1877–1901.
Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y.T., Li, Y., Lundberg, S., et al., 2023. Sparks of arti-ficial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712 .
Cao, N., Cui, W., Cao, N., Cui, W., 2016. Overview of text visualization tech- niques. Introduction to Text Visualization , 11–40.
Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al., 2023. A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 .
Chen, D., Fisch, A., Weston, J., Bordes, A., 2017. Reading Wikipedia to answer open-domain questions, in: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Vancouver, Canada. pp. 1870–1879. URL: https://aclanthology.org/P17-1171, doi:10.18653/v1/P17-1171.
Chen, W., Su, Y., Zuo, J., Yang, C., Yuan, C., Chan, C.M., Yu, H., Lu, Y., Hung, Y.H., Qian, C., Qin, Y., Cong, X., Xie, R., Liu, Z., Sun, M., Zhou, J., 2024. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors, in: The Twelfth International Conference on Learning Representations. URL: https://openreview.net/forum?id=EHg5GDnyq1.
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al., 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) .
Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D., 2023. Do LLMs understand social knowledge? evaluating the sociability of large language models with SocKET benchmark, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Singapore. pp. 11370– 11403. URL: https://aclanthology.org/2023.emnlp-main.699, doi:10.18653/v1/2023.emnlp-main.699.
Clark, H.H., Gerrig, R.J., 1983. Understanding old words with new meanings. Journal of verbal learning and verbal behavior 22, 591–608.
Cowie, H., 2019. From birth to sixteen: Children’s health, social, emotional and linguistic development. Routledge.
De Deyne, S., Warner, S., Perfors, A., 2023. Common words, uncommon meanings: Evidence for widespread gender differences in word meaning., in: Proceedings of the Annual Meeting of the Cognitive Science Society.
Du, Z., Qian, Y., Liu, X., Ding, M., Qiu, J., Yang, Z., Tang, J., 2022. Glm: General language model pretraining with autoregressive blank infilling, in: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 320–335.
![]()
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, H., 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997 .
Geeraerts, D., 2002. The theoretical and descriptive development of lexical semantics. The lexicon in focus. Competition and convergence in current lexicology , 23–42.
Gordon, S., 2022. 16-year-old child development milestones: Your child’s growth and development at age 16. Very well Family. Medically reviewed by a board-certified physician .
H¨aggstr¨om, O., 2023. Are large language models intelligent? are humans?, in: Computer Sciences & Mathematics Forum, MDPI. p. 68.
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Stein- hardt, J., 2021. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR) .
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al., 2023. A survey on hallucination in large lan- guage models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232 .
Jang, J., Ye, S., Seo, M., 2023. Can large language models truly understand prompts? a case study with negated prompts, in: Transfer Learning for Natural Language Processing Workshop, PMLR. pp. 52–62.
Kandpal, N., Deng, H., Roberts, A., Wallace, E., Raffel, C., 2023. Large lan- guage models struggle to learn long-tail knowledge, in: International Con-
ference on Machine Learning, PMLR. pp. 15696–15707. Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y., 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems 35, 22199–22213. Li, Z., 2023. The dark side of chatgpt: legal and ethical challenges from stochastic parrots and hallucination. arXiv preprint arXiv:2304.14347 . Liu, X., Yu, H., Zhang, H., Xu, Y., Lei, X., Lai, H., Gu, Y., Ding, H., Men, K., Yang, K., et al., 2023. Agentbench: Evaluating llms as agents. arXiv preprint arXiv:2308.03688 . Lonergan, B.J., 1957. Insight; a study of human understanding. . Luo, H., Zhang, T., Chuang, Y.S., Gong, Y., Kim, Y., Wu, X., Meng, H., Glass, J., 2023. Search augmented instruction learning, in: Findings of the Association for Computational Linguistics: EMNLP 2023, Association for Computational Linguistics, Singapore. pp. 3717–3729. URL: https://aclanthology.org/2023.findings-emnlp.242, doi:10.18653/v1/2023.findings-emnlp.242. Miller, G.A., 1967. The psychology of communication. Human Resource Man- agement 6, 43. OpenAI, 2023. Introducing chatgpt. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al., 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35, 27730–27744. Pal, A., Umapathi, L.K., Sankarasubbu, M., 2022. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering, in: Conference on Health, Inference, and Learning, PMLR. pp. 248–260. Peng, D., Wei, W., Mao, X.L., Fu, Y., Chen, D., 2023. An empirical study on the language modal in visual question answering, in: Proceedings of the ThirtySecond International Joint Conference on Artificial Intelligence, IJCAI-23, International Joint Conferences on Artificial Intelligence Organization. pp. 4109–4117. URL: https://doi.org/10.24963/ijcai.2023/457, doi:10.24963/ijcai.2023/457. main Track. Qu, Y., Ding, Y., Liu, J., Liu, K., Ren, R., Zhao, W.X., Dong, D., Wu, H., Wang, H., 2021. RocketQA: An optimized training approach to dense passage retrieval for open-domain question answering, in: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, Online. pp. 5835– 5847. URL: https://aclanthology.org/2021.naacl-main.466, doi:10.18653/v1/2021.naacl-main.466. Rai, D., Zhou, Y., Wang, B., Yao, Z., 2023. Explaining large language model-based neural semantic parsers (student abstract), in: Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI Press. URL: https://doi.org/10.1609/aaai.v37i13.27014, doi:10.1609/aaai.v37i13.27014. Riccardi, N., Desai, R.H., 2023. The two word test: A semantic benchmark for large language models. arXiv preprint arXiv:2306.04610 . Robinson, J., Wingate, D., 2023. Leveraging large language models for multiple choice question answering, in: The Eleventh International Conference on Learning Representations. URL: https://openreview.net/forum?id=yKbprarjc5B. Shi, F., Chen, X., Misra, K., Scales, N., Dohan, D., Chi, E.H., Sch¨arli, N., Zhou, D., 2023. Large language models can be easily distracted by irrelevant context, in: International Conference on Machine Learning, PMLR. pp. 31210–31227. Si, C., Gan, Z., Yang, Z., Wang, S., Wang, J., Boyd-Graber, J., Wang, L., 2023. Prompting gpt-3 to be reliable, in: International Conference on Learning Representations (ICLR). URL: https://arxiv.org/abs/2210.09150. Sternberg, R.J., 1983. Components of human intelligence. Cognition 15, 1–48. Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al., 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 . Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., Bowman, S., 2018. GLUE: A multi-task benchmark and analysis platform for natural language understanding, in: Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Association for Computational Linguistics, Brussels, Belgium. pp. 353–355. URL: https://aclanthology.org/W18-5446, doi:10.18653/v1/W18-5446. Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V.,
Zhou, D., et al., 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems 35, 24824–24837.
Xu, R., Lin, H., Han, X., Sun, L., Sun, Y., 2024. Academically intelligent llms are not necessarily socially intelligent. arXiv preprint arXiv:2403.06591 .
Ying, J., Cao, Y., Xiong, K., He, Y., Cui, L., Liu, Y., 2023. Intuitive or depen- dent? investigating llms’ robustness to conflicting prompts. arXiv preprint arXiv:2309.17415 .
Yoran, O., Wolfson, T., Ram, O., Berant, J., 2024. Making retrieval-augmented language models robust to irrelevant context, in: The Twelfth International Conference on Learning Representations. URL: https://openreview.net/forum?id=ZS4m74kZpH.
Yu, W., Iter, D., Wang, S., Xu, Y., Ju, M., Sanyal, S., Zhu, C., Zeng, M., Jiang, M., 2023. Generate rather than retrieve: Large language models are strong context generators, in: The Eleventh International Conference on Learning Representations. URL: https://openreview.net/forum?id=fB0hRu9GZUS.
Zhang, X., Li, C., Zong, Y., Ying, Z., He, L., Qiu, X., 2023. Evaluating the performance of large language models on gaokao benchmark. arXiv preprint arXiv:2305.12474 .
Zhao, P., Zhang, H., Yu, Q., Wang, Z., Geng, Y., Fu, F., Yang, L., Zhang, W., Cui, B., 2024. Retrieval-augmented generation for ai-generated content: A survey. arXiv preprint arXiv:2402.19473 .
Zheng, Y., Zhou, J., Qian, Y., Ding, M., Liao, C., Jian, L., Salakhut- dinov, R., Tang, J., Ruder, S., Yang, Z., 2022. FewNLU: Benchmarking state-of-the-art methods for few-shot natural language understanding, in: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Dublin, Ireland. pp. 501–516. URL: https://aclanthology.org/2022.acl-long.38, doi:10.18653/v1/2022.acl-long.38.
Zhu, K., Wang, J., Zhou, J., Wang, Z., Chen, H., Wang, Y., Yang, L., Ye, W., Gong, N.Z., Zhang, Y., et al., 2023. Promptbench: Towards evaluating the robustness of large language models on adversarial prompts. arXiv preprint arXiv:2306.04528 .